| Operand | Description | Default value |
| Number | File number | sequential |
| Identifier | File name used within ARENA by the READ and WRITE blocks | blank |
| System name | The name recognized by the computer system | - |
| Access type | Sequential, Direct(length) or User | Sequential |
| Structure | File structure : Unformatted, Free format, WKS or format (FORTRAN or C syntax) | Unformatted |
| End of file action | Error, Dispose, Rewind or Ignore | Error |
| Operand | Description | Default |
| File_ID | File to be read from (integer file number or name or STDIN) | STDIN |
| Format | File format (the same options as with the files element) | Format specified in the FILES element or FREE for STDIN |
| Record number | Record number to read | Next record |
| Variables | List of variables to read | - |
| 126 | 3 | 22 |
| 51 | 7 | 12 |
| 23 | 10 | 52 |
| 126 | 13 | 15 |
| 12 | 18 | 29 |
| Operand | Default value |
| Number | - |
| Identifier | bus_in |
| System name | TIMETABLE.TXT |
| Access type | Sequential |
| Structure | Free |
| End of file action | Dispose |
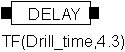
| Block thickness (cms) | Drill time (secs) |
| 1 | 5 |
| 2 | 12 |
| 3 | 20 |
| 4 | 28 |
| 5 | 40 |
| Operand | Description | Default |
| Set number | Number which identifies the set | sequential |
| Set name | The name of the set | - |
| Members | List of members | - |
 WORKSHEET 12 ĹTOO HOT TO HANDLE !ĺ
WORKSHEET 12 ĹTOO HOT TO HANDLE !ĺ
| Type | Percentage | Route | Process time |
| 1 | 30 | 1 | 6,1 |
| 2 | 10,2 | ||
| 3 | 10,2 | ||
| 2 | 45 | 2 | 9,2 |
| 3 | 5,1 | ||
| 1 | 4,1 | ||
| 3 | 25 | 1 | 12,2 |
| 3 | 7,1 | ||
| 2 | 5,2 | ||
| 3 | 4,1 |